当有人问你:“你的光标在哪里?”你会怎么说?可能说“第18行”,或者如果你那天心情不错,而且数字是个位数,你可能会加上列数:“第18行,第5列。”行和列——简单,容易。
文本编辑器,包括 Zed,也使用行和列来描述位置,但是——当我第一次探索 Zed 的代码库时,我惊讶地发现——Zed 中还有很多其他的坐标系。有偏移量、UTF-16 中的偏移量、显示点和锚点。
为了最终理解这些不同的文本坐标系以及何时使用它们,我与 Zed 的两位联合创始人 Nathan 和 Antonio 进行了交谈,并请他们向我详细解释这一切,从 Point 到 DisplayPoint 再到 Anchor。

点
首先,让我们谈谈 zed 中最明显的文本坐标形式:Point。Point 是一个“由行和列组成的文本缓冲区中的零索引点”。它看起来像这样
// crates/rope/src/point.rs
struct Point {
row: u32,
column: u32,
}这没什么好惊讶的。行和列,基本要素。这是一段来自我们某个测试的代码片段,用以说明 Point 的使用方式
let last_selection_start = editor.selections.last::<Point>(cx).range().start;
assert_eq!(last_selection_start, Point::new(2, 0));这里的断言试图确保选择从第3行(零索引!)第0列开始。
Point 的一个便捷特性是它们使得沿行导航变得容易。将光标向下移动一行就像递增 row 值一样简单
let old_point = Point::new(18, 5);
let new_point = Point::new(point.row + 1, point.column);从第18行到第19行,只需简单地 +1。很棒。如果你想回去,就用 -1。但是如果你想左右导航呢?
那可能会变得棘手,因为不同的行可能长度不同。简单地增加或减少列数可能会导致你在文档中获得一个无效的位置。事实证明,Point 表面上的简单性有点具有欺骗性——Point 需要仔细处理。
例如,在 Zed 中,Point 遵循 Nathan 所谓的“打字机逻辑”:回车——本质上是添加一个新行——将列数重置为零,因为在打字机上,滑架也会从下一行的开头开始。
为了说明这一点,这是一个在 Zed 代码库中通过的测试。请注意列
fn test_point_basics() {
let point_a = Point::new(5, 8);
let point_b = Point::new(2, 10);
let result = point_a + point_b;
assert_eq!(result, Point::new(7, 10));
}请注意,这两行 — 5 和 2 — 被加在一起,但结果列是 10,这是 point_b 的 column 值。
使用点进行文本数学运算——不像我想象的那么简单。
偏移
偏移是 Zed 中另一种类型的文本坐标系。它们*很*简单。Offset 是一个绝对数字,它表示文档中从文档开头算起的字节数位置。
文档的开头是 Offset::new(0),Hello World 中 W 的位置是 Offset::new(6),文档中的最后一个字符是 Offset::new(document.len() - 1),假设每个字符都是一个字节。
偏移量在处理跨多行文本的操作时特别有用。例如,选择
let start = Offset::new(10);
let end = Offset::new(50);
let selection = Selection::new(start, end);完全不需要担心列——从这个字符到那个字符,包括换行符。用 Offset 可以很容易地表达。
但是,同样,Offset 也有一个小小的陷阱,因为仅仅 Offset 是不够的。
UTF-16,什么?
在探索 Zed 的代码库时,我发现一个非常有趣的现象,那就是你会发现 OffsetUtf16 的数量远多于 Offset。还有 PointUtf16。我个人从未接触过 UTF-16,除非是与语言服务器和语言服务器协议打交道时,该协议使用 UTF-16 编码来计算和描述文本文档的位置和偏移量。
事实证明,这正是 Zed 拥有 OffsetUtf16 和 PointUtf16 的原因:与语言服务器通信。例如,以下是一个方法,它查找给定缓冲区位置的定义
fn definition<T: ToPointUtf16>(
&self,
buffer: &Model<Buffer>,
position: T,
cx: &mut ModelContext<Self>,
) -> Task<Result<Vec<LocationLink>>> {
let position = position.to_point_utf16(buffer.read(cx));
self.definition_impl(buffer, position, cx)
}该位置——一个实现了 ToPointUtf16 trait 的 T——在发送到语言服务器之前会被转换为一个 PointUtf16。在底层,这可能最终会调用我们的 Rope 数据结构上的以下方法
// crates/rope/src/rope.rs
impl Rope {
fn point_to_point_utf16(&self, point: Point) -> PointUtf16 {
if point >= self.summary().lines {
return self.summary().lines_utf16();
}
let mut cursor = self.chunks.cursor::<(Point, PointUtf16)>();
cursor.seek(&point, Bias::Left, &());
let overshoot = point - cursor.start().0;
cursor.start().1
+ cursor.item().map_or(PointUtf16::zero(), |chunk| {
chunk.point_to_point_utf16(overshoot)
})
}
}为了理解这里的每一行,我建议阅读 Zed Decoded 中关于 Rope 和 SumTree 数据结构的文章。目前只需知道,我想表达的重点是:由于语言服务器,UTF-16 对 Zed 如此重要,以至于实现 Rope 的 SumTree 已经索引了 UTF-16 点和偏移量,从而产生了两个新的文本坐标系统——PointUtf16 和 OffsetUtf16——并且使得与 UTF-16 之间的转换非常快速。
显示点
如果我们爬上抽象阶梯,抛开偏移量、行和列,接下来我们就会遇到 DisplayPoint。DisplayPoint 是什么?
// crates/editor/src/display_map.rs
struct DisplayPoint(BlockPoint)一个 DisplayPoint 是围绕 BlockPoint 的新类型。BlockPoint 是什么?
// crates/editor/src/display_map/block_map.rs
struct BlockPoint(pub Point);一个 BlockPoint 是一个... Point——等等,什么?那是不是意味着我们根本没有爬上抽象阶梯,而是在抽象仓鼠轮里转了一圈?
不完全是!DisplayPoint *是*一个 Point,没错,但在此上下文中——在 DisplayPoint 内部和 editor crate 内部——Point 的行和列具有不同的含义。它们指的不是磁盘上文本文件中的对应部分,而是你在编辑器中可以*看到*的行和列,即*显示*的行和列。因此叫做 DisplayPoint。
看看这个截图
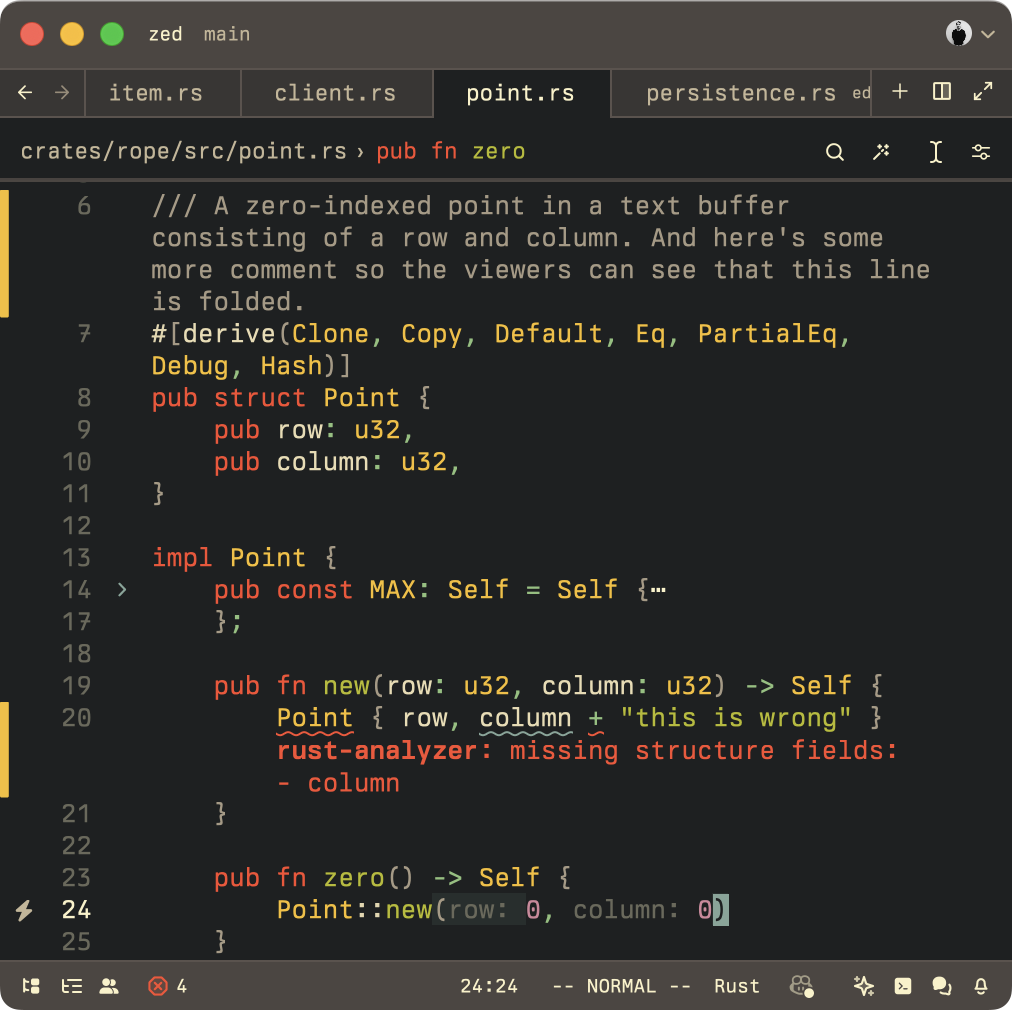
光标的位置是什么?仔细看。作为普通的 Point(零索引!),它将是第 23 行,第 23 列。但作为 DisplayPoint,光标的位置是第 29 行,第 36 列!
那是因为 DisplayPoint 描述了 DisplayMap 上的一个位置(我们希望在未来的 Zed Decoded 剧集中会详细介绍),并考虑了
- 软换行
- 折叠
- 嵌入式提示
- 制表符
- 块和折痕
在该截图中,你可以看到第6行进行了软换行,占据了不止一行。Point::MAX 的定义被折叠了。一个块显示了一个诊断错误。而在光标所在的 zero() 方法中,光标左侧有两个嵌入式提示。
DisplayPoint 允许 Zed 考虑到所有这些因素,并准确描述光标的位置——在换行、诊断、折叠、内联提示等等之间。
这是我发现一个非常能说明 DisplayPoint 作用的测试的修改版本
// Modified version of a test in crates/editor/src/display_map.rs
async fn test_zed_decoded(cx: &mut gpui::TestAppContext) {
// [... setup ...]
let font_size = px(12.0);
let wrap_width = Some(px(64.));
let text = "one two three four five\nsix seven eight";
let buffer = MultiBuffer::build_simple(text, cx);
let map = cx.new_model(|cx| {
DisplayMap::new(
buffer.clone(),
font("Helvetica"),
font_size,
wrap_width,
// [... other parameters ...]
)
});
let snapshot = map.update(cx, |map, cx| map.snapshot(cx));
// Given the above constraints — font_size, wrap_width, ... — the text above
// is displayed in 5 lines.
assert_eq!(
snapshot.text_chunks(DisplayRow(0)).collect::<String>(),
"one two \nthree four \nfive\nsix seven \neight"
);
// DisplayPoint(1, 0) is equivalent to Point(0, 8)
assert_eq!(
DisplayPoint::new(DisplayRow(1), 0).to_point(&snapshot),
Point::new(0, 8)
);
// DisplayPoint(1, 2) is equivalent to Point(0, 10)
assert_eq!(
DisplayPoint::new(DisplayRow(1), 2).to_point(&snapshot),
Point::new(0, 10)
);
// DisplayPoint(4, 1) is equivalent to Point(1, 11)
// (This is the "i" in "eight")
assert_eq!(
DisplayPoint::new(DisplayRow(4), 1).to_point(&snapshot),
Point::new(1, 11)
);
}这个测试是这样说的:给定文本...
one two three four five
six seven eight...以及12像素的字体大小,64像素的换行宽度,Helvetica字体,以及一堆其他参数,文本将这样显示
one two
three four
five
six seven
eight而 DisplayMap(这里是局部变量 snapshot 中的快照)允许我们在“真实”的 Point 和 DisplayPoint 之间进行转换
Point::new(0, 10)显示在DisplayPoint::new(1, 2)Point::new(1, 11)显示在DisplayPoint::new(4, 1)
很酷,不是吗?
这里面有很多我乐意深入探究的底层机制,但我们已经聊得够久了,所以让我们转向下一个坐标系。或者至少是我原以为是坐标系但结果不是的东西:锚点。
锚点
在与 Nathan 和 Antonio 对话之前(你可以在这里观看配套视频),我知道锚点——我在代码库中见过 Anchor 类型和各种相关方法——并且假设它们是表示文本文档中位置的另一种方式——另一个坐标系。
结果证明,这个假设有点错误。锚点*确实*与文本文档中的位置有关,但与 Points、Offsets 或 DisplayPoint 非常不同。
假设你有一个这样的文本文档
Hello World!一个 Anchor 允许你指向此文档中给定字符的一侧——左侧或右侧。例如,你可以创建一个指向 W 左侧的锚点。那将接近 Point::new(0, 6),但又不太一样:Point 描述了此文档此版本中 W 的位置,而 Anchor 则会一直附着在 W 的一侧,即使它被编辑了。
用 Nathan 的话来说
一个锚点是一个逻辑坐标。你可以在字符的右侧或左侧创建一个锚点。然后,在未来的任何时候,你都可以兑现该锚点,并获取你本质上标记或锚定的字符位置。即使在此期间发生了编辑,即使该代码已被删除,或者该字符已被删除,你仍然可以获得其墓碑的位置——如果它没有被删除,它会出现在哪里,或者如果撤销删除,它会出现在哪里。
因此,如果我们将一个锚点附加到上面 W 的左侧,然后文本文档被编辑成这样
Hello and good day to you, World!我们仍然可以取出我们的锚点并“兑现”它,将其转换为 W 现在实际所在的 Point。
这对于协同文本编辑器来说完全合理:如果你的光标停留在 W 上,而有人在左侧编辑文本,你希望你的光标仍然停留在 W 上,而不是随着光标下方的文本变化而移动。
如果你查看Anchor 的定义,你会发现它与 Zed 的协作特性和CRDTs 的关联是多么紧密
// crates/text/src/anchor.rs, slightly simplified
/// A timestamped position in a buffer
struct Anchor {
timestamp: clock::Lamport,
/// The byte offset in the buffer
offset: usize,
/// Describes which character the anchor is biased towards
bias: Bias,
buffer_id: Option<BufferId>,
}这里的 timestamp 是一个 Lamport 时间戳,一个*逻辑*时间戳。在我们的对话中,Antonio 说 timestamp 在这里不是一个好名字,它以前叫做 id,这也是一种更好的思考方式。Nathan 解释道
在 CRDT 中,或者至少在我们的 CRDT 实现中,每一段文本,无论是字符还是大块粘贴的文本或其他插入的内容,都被视为一个不可变块。该不可变块被赋予一个唯一的 ID,一个在集群中唯一的 ID。
上面提到的 timestamp: clock::Lamport 就是这个 ID。Nathan 继续说道
[...]基本上,这是一种获取唯一ID的方式,对吗?唯一性继承自副本ID,然后每个副本当然可以自由地通过增加它们的序列号来全天生成新的Lamport时间戳。它实际上是插入的ID,是原始插入文本块的ID。
所以,timestamp 是分配给不可变文本块的唯一 ID。offset 描述了 Anchor 在这段不会改变的文本中的位置,因为它仍然是不可变的。Nathan 谈到了不可变性
一旦我们插入它,它就是不可变的。如果你删除其中的一部分,我们可能会隐藏它们,墓碑化它们,但它们仍然存在。这就是我们实现协作的方式。整个过程是单调递增的。它只会随着时间的推移而积累数据。正因为如此,我能够引用插入 ID,无论是什么,偏移量,无论是什么。现在有很多索引和奇妙的东西来确定它现在确切的位置。但它至少是我们能够稳定引用的东西。这就是我们选择锚定它的原因。
用 Nathan 的话来说,Anchor 是“这个单调增长结构中的一个锚点。”
但最酷的部分在于:这不仅仅对协作有用!锚点也用于文本的后台处理。试想一下:你想要将一段文本发送给,比如说,一个在后台运行的语言服务器。你创建两个锚点——选择的开始和结束——然后启动一个后台进程,使用这两个锚点将文本发送给语言服务器。与此同时,用户可以继续打字和更改文本,因为这两个锚点将永远有效,因为它们锚定在一个不可变文本片段中的位置。
好了,Point、Offset、UTF-16 对应物、DisplayPoint、Anchor——谁能想到我们会从行和列转向 Lamport 时钟呢?