几周前,我看到了 Antonio 的一个 PR,标题是“加速 Rope 中的点位转换”——谁会不停下来仔细看看这个标题的 PR 呢?
描述已经与标题相符。它包含基准测试结果,告诉我我们 Rope 上一个名为 point_to_offset 的方法现在快了 70%。70%!吞吐量增加了 250%。(我不记得了,但我肯定在我看到这些数字时发出了那种印象深刻的口哨声。)
然后是代码。我滚动浏览了差异,在鼠标滚轮的第四次移动后,我停在了这个片段上
#[inline(always)]
fn nth_set_bit_u64(v: u64, mut n: u64) -> u64 {
let v = v.reverse_bits();
let mut s: u64 = 64;
// Parallel bit count intermediates
let a = v - ((v >> 1) & (u64::MAX / 3));
let b = (a & (u64::MAX / 5)) + ((a >> 2) & (u64::MAX / 5));
let c = (b + (b >> 4)) & (u64::MAX / 0x11);
let d = (c + (c >> 8)) & (u64::MAX / 0x101);
// Branchless select
let t = (d >> 32) + (d >> 48);
s -= (t.wrapping_sub(n) & 256) >> 3;
n -= t & (t.wrapping_sub(n) >> 8);
// [...]
}好的,好的,好的——“并行位计数中间量”,“无分支选择”在一个导致 75% 速度提升的 PR 中——我懂了。我需要知道整个故事。这不可能不有趣。
所以我问 Antonio 位操作是怎么回事,他不仅主动向我介绍了他的优化,还说我们应该结对并添加另一个优化,以使 Rope 在处理制表符时更快。
而且——我很幸运——我们就是这么做的。我们录制了整个结对会话,所以你也可以观看,现在我将与你分享我迄今为止在我们的 Rope 上学到的所有位操作优化知识。

加速点位转换
首先,让我们看看 Antonio 是如何加速 Rope 中的“点位转换”以及这到底意味着什么。
如果你读过我们关于Rope & SumTree 的文章,你已经知道了:我们的Rope 不是一个 真正的 Rope,而是一个穿着风衣的 SumTree,在 Antonio 做出改变之前大致是这样的
struct Rope {
chunks: SumTree<Chunk>
}
struct Chunk(ArrayString<128>);它是一个 Chunk 的 B-树,而一个 Chunk 只不过是一个最大长度为 128 字节的栈分配字符串。
这就是你需要的所有背景知识——我们的 Rope 是一个由 128 字节字符串组成的 B 树。
问题
那么点位转换是什么?用代码表示,它大致相当于这个
struct Point {
row: u32,
column: u32,
}
impl Rope {
fn offset_to_point(&self, offset: usize) -> Point;
}点位转换意味着:获取字符串(表示为 Rope)中的任意偏移量,并将其转换为一个 Point——如果将光标移动到给定偏移量,光标将落在的行和列。
可以想象,这个方法在文本编辑器中很常用。Zed 从各种来源获取偏移量,必须将它们转换为行和列——当你移动文件和编辑时,每秒数千次。
现在想象一下你会如何实现 offset_to_point 方法。
概念上,你需要做的是遍历文件中的每个字符,计算你遇到的换行符和字符,并在达到你的偏移量时停止。然后你就知道你在哪一行了。
我们的 Rope 也是这样做的。
如果你调用 rope.offset_to_point(7234),Rope 会遍历其 SumTree 以找到包含偏移量 7234 的 Chunk,然后在该 Chunk 上,它会再次调用 offset_to_point。而 Chunk 上的 那个 方法看起来与这段代码非常相似
fn offset_to_point(text: &str, offset: usize) -> Point {
let mut point = Point { row: 0, column: 0 };
for (ix, ch) in text.char_indices() {
if ix == offset {
break;
}
if ch == '\n' {
point.column = 0;
point.row += 1;
} else {
point.column += 1;
}
}
point
}这很简单:以 Point 的形式设置一个计数器,遍历 128 字节字符串中的所有字符,并在遇到换行符时记录下来。
但这正是问题所在:虽然 Rope 可以以 O(log(n)) 的时间复杂度将我们带到正确的 Chunk,但我们仍然必须遍历 128 个字符并手动计算换行符——就像原始人一样。
你可能会说 128 个字符不多,这样一个小循环不会造成什么危害,但请记住:我们正在谈论一个支持多个光标并同时与多个语言服务器通信的文本编辑器——这个循环执行得如此频繁,以至于它摸起来都很烫。我们希望它尽可能快。
而这正是 Antonio 所实现的。
优化
Antonio 发现,我们不需要每次查找换行符时都遍历 128 个字符,而是可以一次性完成并记住它们的位置,从而有效地为 Chunk 构建一个索引。
而这样一个索引所需要的一切只是一个 u128。
u128 是 Rust 的 128 位无符号整数类型,而且,嘿,128——这正是 Chunk 中的字节数。
一个 u128 足以记住 Chunk 中给定字节是否具有某个属性。例如,如果 Chunk 中对应的字节是换行符,我们可以在 u128 的给定位置设置一个位为 1。或者我们可以翻转位来记住一个字符占用多少字节——在 UTF-8 和表情符号中,这可能不止一个字节。
这就是 Antonio 的 PR 所做的。我们的 Chunk 现在看起来像这样
struct Chunk {
chars: u128,
chars_utf16: u128,
newlines: u128,
text: ArrayString<128>,
}但这到底是如何运作的?它能给我们带来什么?这真的比遍历字符更好吗?
为了说明这个想法,我们只关注换行符,并使用 u8 而不是 u128——展示和计数的位数更少,但原理相同。
在 u8 中索引换行符
假设我们有以下文本
ab\ncd\nef
我们可以使用以下代码在 u8 中索引换行符的位置
fn main() {
let text = "ab\ncd\nef";
let newlines = newline_mask(text);
// ...
}
fn newline_mask(text: &str) -> u8 {
let mut newlines: u8 = 0;
for (char_ix, c) in text.char_indices() {
newlines |= ((c == '\n') as u8) << char_ix;
}
newlines
}运行这段代码后,我们得到一个 newlines 位掩码,它看起来像这样
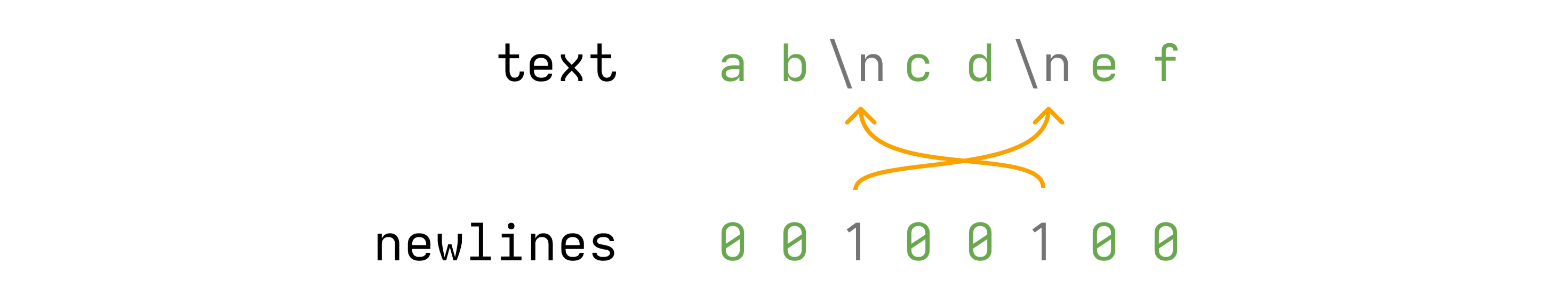
newlines 现在告诉我们 text 中的第 3 和第 6 个字符是换行符。太棒了。现在有了 newlines,回到我们最初的问题:将偏移量转换为 Point。
newlines 是如何帮助解决这个问题的呢?
假设我们的 offset 是 4,文本是 "ab\ncd\nef"。我们想知道字符 d 在哪一行和哪一列。
我们可以这样使用 newlines 来找出答案
struct Point { row: u8, column: u8 }
fn offset_to_point(newlines: u8, offset: usize) -> Point {
let mask = if offset == MAX_LEN {
u8::MAX
} else {
(1u8 << offset) - 1
};
let row = (newlines & mask).count_ones() as u8;
let newline_ix = u8::BITS - (newlines & mask).leading_zeros();
let column = (offset - newline_ix as usize) as u8;
Point { row, column }
}我们首先创建一个 mask,其中所有位都被设置为 1,直到我们感兴趣的偏移量
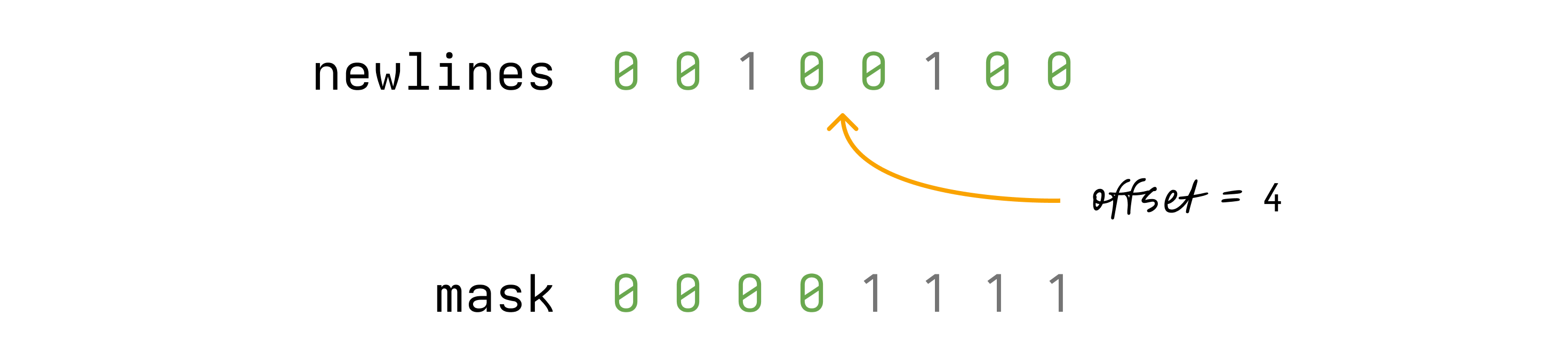
然后我们将这个 mask 与传入的 newlines 进行按位与操作

这样,只有我们感兴趣的偏移量之前的换行符位被设置。现在,要找出我们的偏移量在哪一行,我们所要做的就是计算剩余的设置为 1 的位数。就是这一行
let row = (newlines & mask).count_ones() as u8; // row = 1那是偏移量所在的行——在我们的例子中是 1。它是零索引的,这意味着当与人类而不是计算机交谈时,我们会说字符 d 在第 2 行。
下一步是确定列。为此,我们需要计算我们感兴趣的 offset 与最后一个换行符之间的距离,因为这 就是 列:从最后一个换行符开始的字符数。
这一行首先为我们提供了最接近我们偏移量的换行符位置
let newline_ix = u8::BITS - (newlines & mask).leading_zeros();在我们的例子中,newline_ix 是 3

然后我们将其插入到下一行
let column = (offset - newline_ix as usize) as u8;这给我们提供了列 1。
结果:ab\ncd\nef 中偏移量 4 转换为 Point { row: 1, column: 1 }——第二行,第二列。
它的美妙之处
再看看上面这两行
let row = (newlines & mask).count_ones() as u8;
let newline_ix = u8::BITS - (newlines & mask).leading_zeros();count_ones() 和 leading_zeros()——听起来很像在循环计数这些一和零,对吧?
但不是,这正是美妙之处!count_ones 和 leading_zeros 都通过单个 CPU 指令实现。无需循环。事实证明,CPU 对零和一处理得相当好。
不仅如此,我们现在还减少了指令数量,并且减少了 分支 指令,无分支编程 通常可以在热循环中带来巨大的速度提升。
如果我们将 offset_to_point 的两种版本——一种带循环,一种带位掩码——放入一个微基准测试,并使用实际的 u128 而不是 u8 来使结果更明显,我们可以看到无循环、无分支的版本快了多少
Running benches/benchmark.rs (target/release/deps/benchmark-21888b29446a33c0)
offset_to_point_u128/loop_version
time: [56.914 ns 57.001 ns 57.096 ns]
offset_to_point_u128/mask_version
time: [1.0478 ns 1.0501 ns 1.0529 ns]
带循环是 57ns,带位掩码是 1ns——快了 57 倍。印象深刻的口哨声。
当然,关于微基准测试的所有免责声明都适用,在我们的生产代码中,结果并没有那么显著,但仍然非常好:我一开始提到的 70% 的加速是真实的。
索引制表符
受这一切的启发和激励,Antonio 和我着手为制表符添加相同的索引。
“制表符?”你可能会说,“我不用制表符。”是的,你不用,但 Zed 不知道,仍然需要检查你的行首是否有制表符才能正确显示它们。
制表符很棘手。你不能像显示其他字符那样显示制表符。制表符是……动态的,姑且这么说吧。
字符串 \t\tmy function 的显示方式取决于你配置的制表符大小:如果制表符大小为四,则 \t\t 应显示为八个空格。如果为二,则为四个空格。
“可怜的文本编辑器开发者,”你可能会想,“他们必须乘数字。”感谢你的同情,但是,听着,这还不是全部。
考虑这段文本
ab\t\tline 1
\t\tline 2
如果制表符大小为 4 且启用硬制表符,则应如下显示
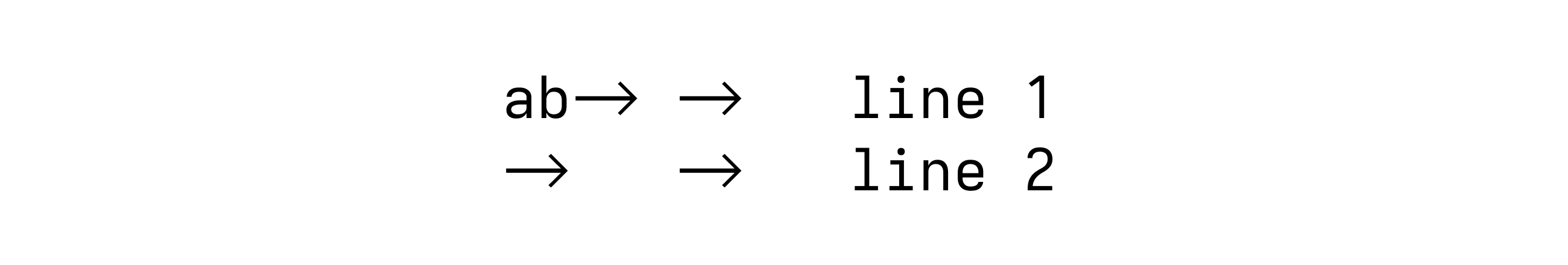
没错——第一行中的第一个制表符只占两个空格,而其他所有制表符都占四个空格。
你看:制表符很棘手,而且,事实证明,也很耗费资源。
在性能分析中,Antonio 发现我们花费大量时间来确定给定文件中制表符的位置和数量。大量时间。
因此,我们在结对会话中做的是为制表符添加了一个索引,其工作方式与换行符索引相同
struct Chunk {
chars: u128,
chars_utf16: u128,
newlines: u128,
// We added this field:
tabs: u128
text: ArrayString<128>,
}它能让 Zed 更快吗?
我们拭目以待。这次我们只添加了索引,但实际上还没有更改更高层的代码来使用它。我们将在下一集 Zed Decoded 中完成。
在那之前,观看配套视频中的完整配对会话,了解所有细节是如何实现的。