大约两个月前,@maxdeviant 和我启动了使 Zed 可扩展的项目。在代码编辑器中,可扩展性可以包括许多需要不同功能的功能,但对于项目的第一阶段,我们专注于可扩展的语言支持。我们希望人们能够使用任何编程语言在 Zed 中进行编码,而不仅仅是少数几种。我们刚刚达到了第一个里程碑,所以现在似乎是分享我们所做工作的好时机。
Zed 中的语言支持
Zed 有两类我们使其可扩展的特定语言功能
-
基于 Tree-sitter 对单个源文件进行进程内基于语法的分析。这需要为每种受支持的语言提供一个 Tree-sitter 语法,以及一组 Tree-sitter 查询,这些查询描述了如何使用该语法的语法树来完成语法高亮、自动缩进等任务。有关 Zed 如何使用 Tree-sitter 查询的更多信息,请参阅我之前的博客文章。
-
通过 语言服务器协议 提供语义理解的外部服务器。这需要指定如何运行给定的语言服务器,如何安装和升级该服务器,以及如何调整其输出(补全和符号)以匹配 Zed 的样式。
在这第一篇文章中,我将重点关注 Tree-sitter 部分。我们将在后续博客文章中描述我们如何处理可扩展的语言服务器。
打包解析器的挑战
允许扩展程序向 Zed 添加 Tree-sitter 解析器的难点在于 Tree-sitter 解析器以 C 代码 的形式表达。语法用 JavaScript 编写,并由 Tree-sitter CLI 转换为 C 代码。Tree-sitter 以这种方式设计是出于多种原因。简而言之,需要某种图灵完备的语言,而 C 代码具有有用的特性,即它可以通过 C 绑定从几乎任何高级语言中消费。但遗憾的是,C 代码并不是分发给最终用户最方便的工件。
一种可能的扩展分发方法是发布 C 代码本身,在用户安装扩展时使用他们的 C 编译器在用户机器上编译它,然后动态加载生成的共享库。这基本上就是我们对 Atom 所做的工作(使用 Node.js 打包设施)。其他使用 Tree-sitter 的编辑器,如 Neovim 和 Helix,也使用 这种 相同的方法。
但对于 Zed,我们希望获得流畅、安全的插件安装体验,不依赖于用户的 C 编译器。我们希望让扩展程序不可能导致 Zed 崩溃。Tree-sitter 解析器主要由相当安全的自动生成 C 代码组成,但语法作者也可以编写包含任意逻辑的外部扫描器,我们曾遇到因第三方外部扫描器中的错误导致的崩溃。如果我们将扩展程序直接作为共享库加载,我们将永远无法防止此类崩溃。
显然,我们使用了 WebAssembly。但是如何实现?
你可能不会惊讶地发现解决方案涉及 WebAssembly。我之前已经为 Tree-sitter 构建了一个 WebAssembly 绑定,它允许你通过 JavaScript API 在 Web 上运行 Tree-sitter 解析器。WebAssembly(简称 wasm)是分发解析器的一种极好的格式,因为它跨平台,并且旨在安全地运行不受信任的代码。
然而,在我们的原生代码编辑器中,如何使用解析器的 wasm 构建并不明显。
当你运行一个 wasm 程序时,你的应用程序会向该程序提供一个字节数组,作为其线性内存。wasm 代码只能读写这些字节。但在 Zed 中,当运行一个解析器时,需要交换大量数据。每次按键时,Zed 需要传入源代码,解析器需要返回一个具体语法树——一个比相应文本大得多的数据结构。当增量解析时,每个语法树与前一个语法树共享公共结构,并且 Zed 经常将这些语法树发送到后台线程,在那里它们用于各种异步任务。
因此,如果我们将解析器完全通过 wasm 运行,我们每次解析都需要从 wasm 内存中复制大量数据。所以简单地将 Tree-sitter 和语法编译成 wasm 是不够的。
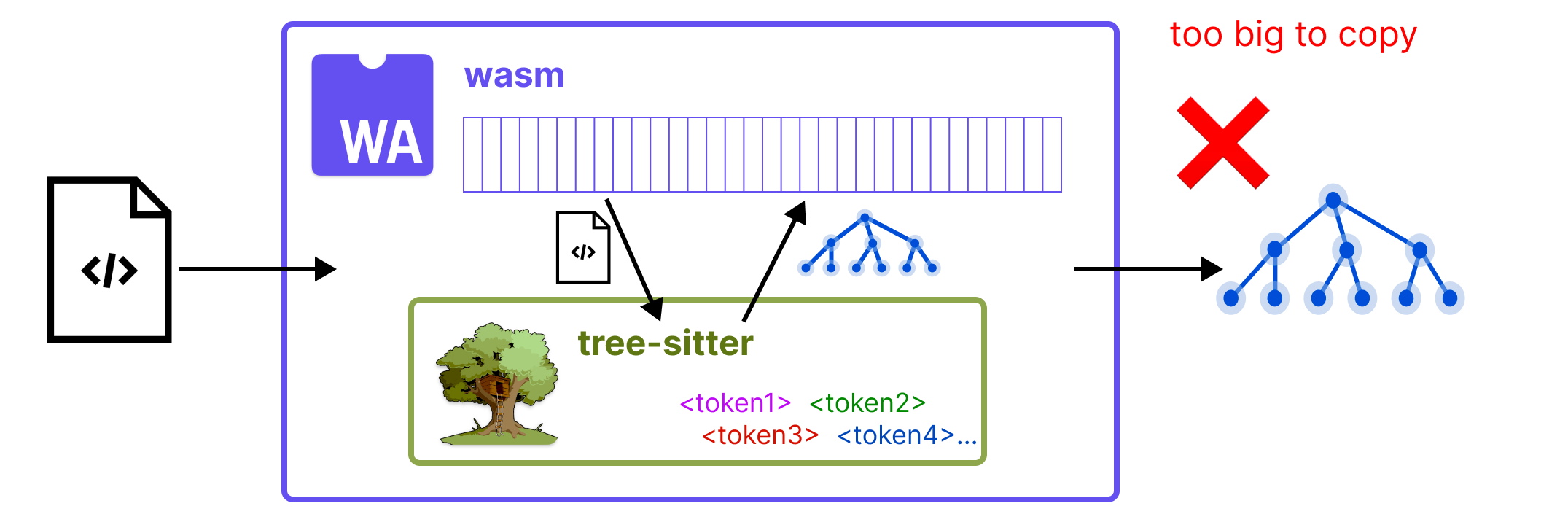
混合原生 + WebAssembly 系统
我们决定利用 Tree-sitter 解析器是表驱动的事实。大部分生成的 C 代码由表示状态机的静态数组组成。
与其他表驱动解析框架一样,Tree-sitter 的解析分为两部分。词法分析阶段逐字符处理文本,生成标记。每个语法的词法分析器都实现为一些自动生成的 C 函数和一些可选的手写函数。解析阶段更为复杂,是实际构建语法树的地方。关键的是,解析完全由静态数据驱动。

这两个阶段之间的划分,使得我们能够采用一种独特的架构,即我们从 wasm 文件加载解析器,但该 wasm 文件中的大部分静态数据都从 wasm 线性内存复制到原生数据结构中。在解析过程中,当我们需要运行词法分析函数时,我们使用 WebAssembly 引擎,但所有其余的计算都是原生完成的,其方式与使用原生编译的 Tree-sitter 解析器完全相同。
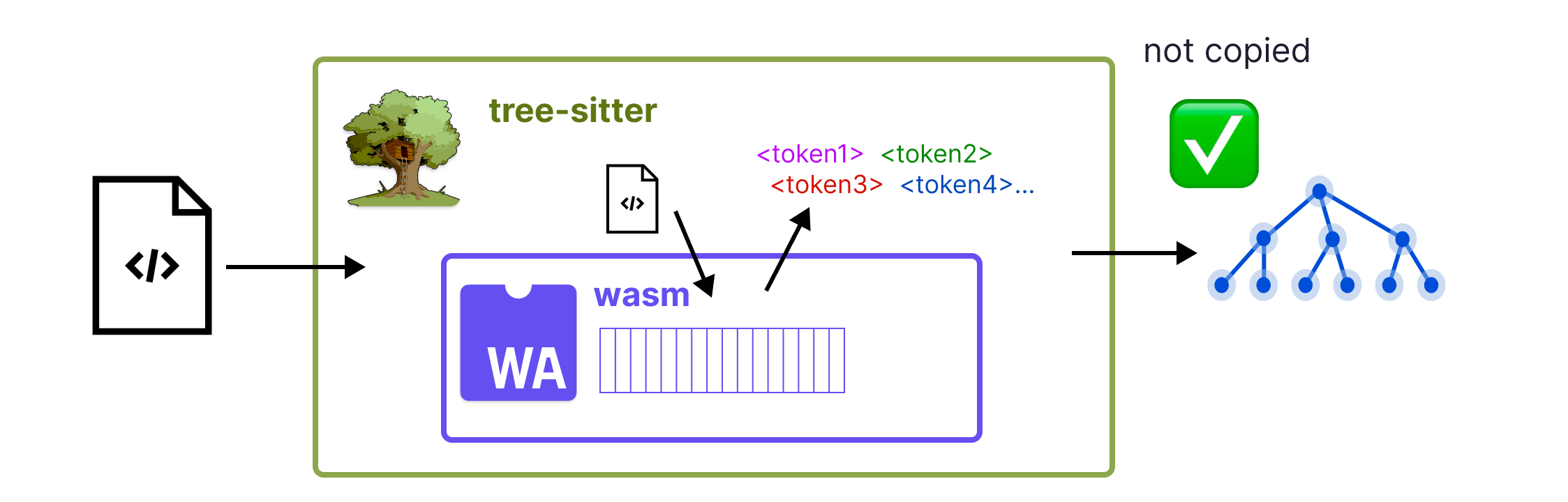
词法分析是解析过程中开销最小的部分,也是唯一涉及自定义手写代码的部分。因此,在许多方面,这种混合原生 + wasm 设计为我们提供了安全性与性能的理想组合。
扩展 Tree-sitter API
为了实现这种新的解析方法,我们向 Tree-sitter 库添加了一些新的原语。
作为背景,Tree-sitter 核心库提供了一个 Parser 类型,用于解析源代码,创建 Tree 对象。要使用解析器,您必须为其分配一个 Language,这是一个从特定语法生成的不透明对象,并在该语法的单独库中提供。
let mut parser = tree_sitter::Parser::new();
let python_language = tree_sitter_python::language().unwrap();
parser.set_language(&python_language).unwrap();
let tree = parser.parse("def secret():\n return 42\n", None).unwrap();我们添加了一个名为 WasmStore 的新类型,它与 Wasmtime wasm 引擎集成,并允许您从 WASM 二进制文件创建 Language 实例。这些语言对象的功能与正常的原生语言对象完全相同,不同之处在于,在使用它们时,您的解析器需要分配一个 WasmStore。这是必需的,因为 wasm 存储允许解析器在词法分析期间调用 wasm 函数。
let engine = wasmtime::Engine::default();
let mut wasm_store = tree_sitter::WasmStore::new(&engine);
const WASM_BYTES: &[u8] = include_bytes!("tree-sitter-python.wasm");
let python_language = wasm_store.load_language("python", WASM_BYTES).unwrap();
parser.set_wasm_store(wasm_store);
parser.set_language(&python_language).unwrap();除了这一个区别,从 WASM 加载的语言与原生编译的语言行为完全相同。生成的语法树是相同的,并且不与 wasm 存储耦合。
实现亮点
与 Tree-sitter 库的其余部分一样,这些新的 API 是用 C 实现的。它们使用了 Wasmtime 出色的 C API。您可以在这里找到它们的完整实现。
使用 wasm 时,您可以对模块如何链接和加载的细节进行非常低级的控制。模块声明了几个控制 wasm 线性内存布局的常量的导入——它们的静态数据应放置的地址、调用堆栈的基地址以及堆的起始地址。以下是 tree-sitter WasmStore 的 wasm 内存布局图

模块还声明了它们所依赖的所有函数的导入。如上所述,Tree-sitter 语法可以包含称为外部扫描器的手写源文件。这些文件通常使用 C 标准库中的函数——字符分类函数,如 iswalpha/iswspace,字符串处理函数,如 strlen/strncmp,以及用于承载少量状态的内存管理函数,如 malloc/free。为了处理这些导入,Tree-sitter 库嵌入了一个小的 wasm blob,其中包含 libc 中的一部分函数,这些函数可供外部扫描器使用。
提供我们自己的迷你 libc 的一个很酷的地方是,我们不需要使用标准版本的内存分配函数 malloc、free 等。我们知道外部扫描器分配的内存仅在单个解析期间需要,所以我们实现了我们自己的微型 malloc 库,它使用 bump-allocation。这种分配器比通用 malloc 实现的开销小得多,并且需要的 wasm 代码也少得多。最棒的是,它使得外部扫描器不可能导致内存泄漏!我们可以在每次解析开始时简单地重置整个 wasm 堆。
使用语言扩展
这个功能发布后,Zed 社区立即开始发布语言扩展。Zed 扩展商店中当前的语言扩展数量为 6️⃣7️⃣ 个,并且还在持续增长。这些语言支持 Zed 的所有语法感知功能:语法感知选择、大纲视图、基于语法的自动缩进,当然还有语法高亮。
要浏览扩展,请在应用程序菜单中单击 Zed > Extensions。如果您使用的语言尚未受支持,我们邀请您在我们的扩展仓库上提交 PR。或者只需提交一个问题并寻求帮助。请参阅“开发扩展”文档以开始使用。
结语
使用 wasm 打包 Tree-sitter 语法对于 Zed 来说效果非常好,Wasmtime 引擎也非常棒。Tree-sitter 语法只是 Zed 扩展系统的一部分。在后续文章中,我们将讨论我们使用 wasm 使 Zed 可扩展的其他所有方式。感谢您的阅读!